




400-667-5666
Mon-Sun 9:00-21:00
 中文
中文

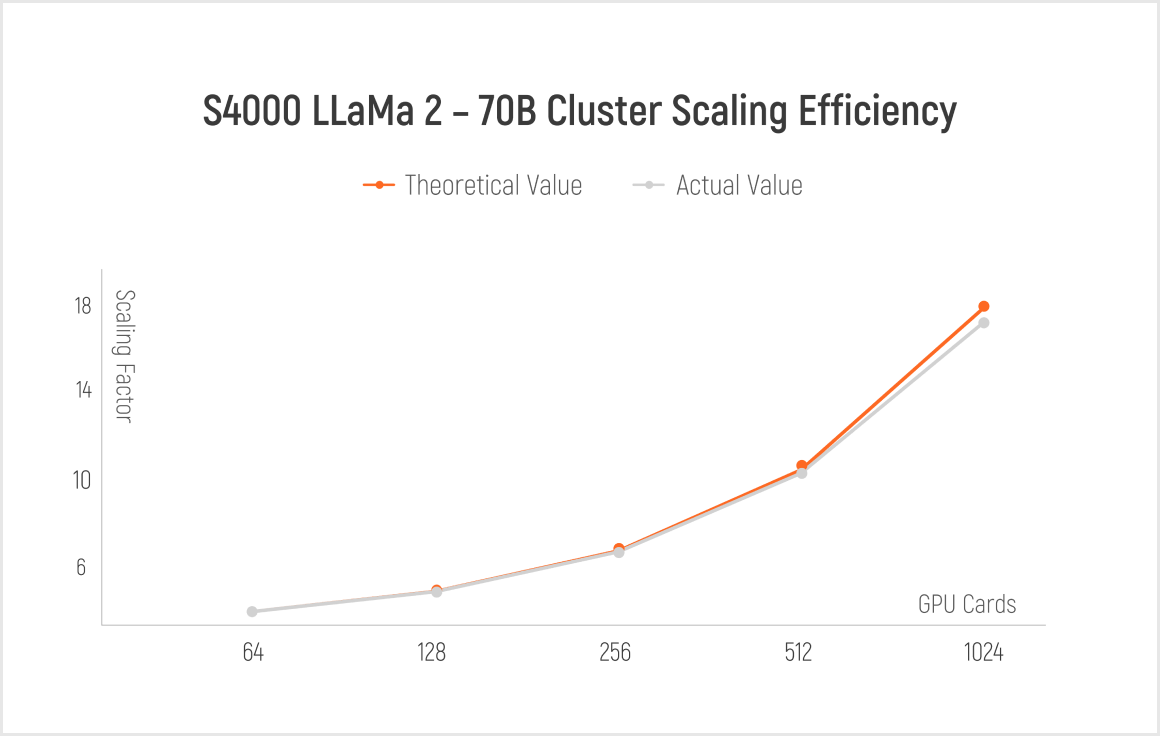
MTT S4000, equipped with 128 Tensor Cores and 48 GB of memory, effectively supports inference for mainstream LLMs, such as LLaMa, ChatGLM, Qwen, and Baichuan.
A training, finetuning, and inference platform for developers of LLM apps. It is based on Moore Threads' GPUs and models.
A software for high-performance and distributed inference services, supporting backend models such as LLMs, image and video generation, and traditional AI.
A distributed inference acceleration framework for Moore Threads' GPUs. It achieves inference acceleration for LLMs based on transformer architectures.
An inference acceleration framework for Moore Threads’ GPUs. It is ideal for inference acceleration in image and video generation and traditional AI.
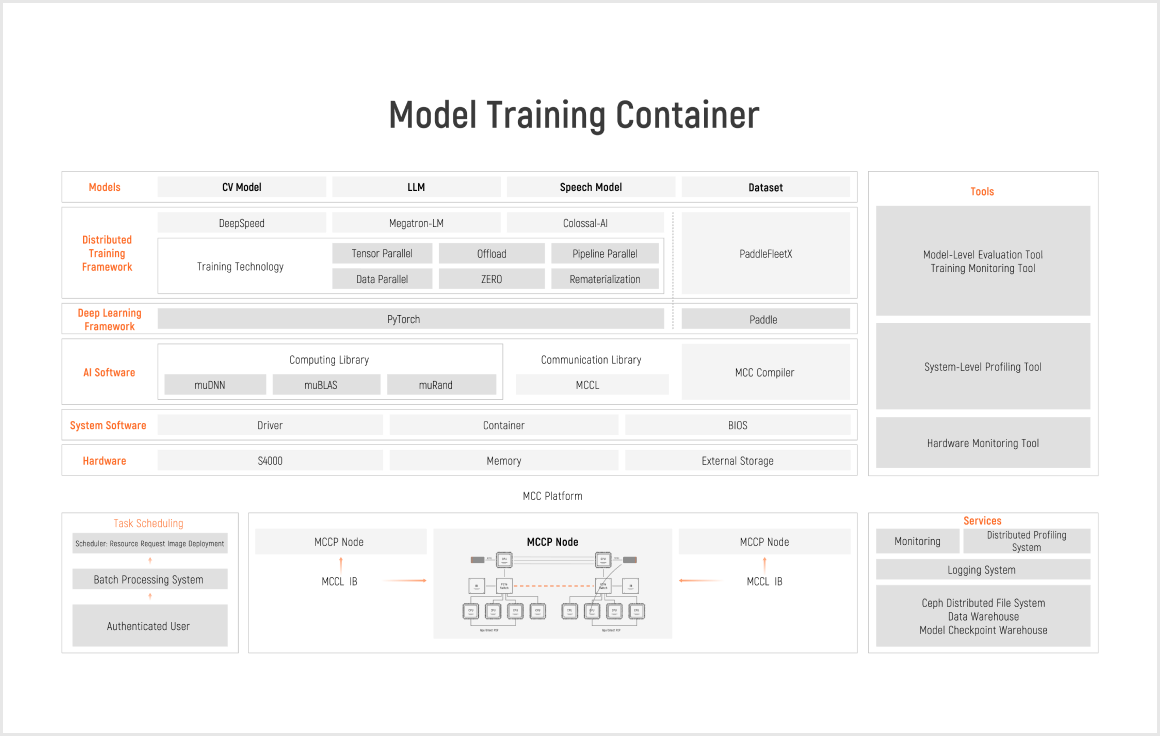
Optimized server for clusters to train large models, providing excellent support for Moore Threads Full-Stack Solution for AI Data Centers.


Mon-Sun 9:00-21:00

