400-667-5666
Mon-Sun 9:00-21:00
 中文
中文

MTT KUAE is Moore Threads Full-Stack Solution for AI Data Centers. It based on MTT S5000 GPU and the dual-processor 8-GPU server MTT SGX5000. This integrated solution tackles the challenges inherent in deploying large-scale GPU computing power with efficiency and effectiveness.

Cluster construction in 30 days

Optimization of computing power, storage, and networking

Complete suite of intuitive tools and software stack

Distributed training for trillion-parameter models
MTT KUAE full-stack solution is built on Moore Threads' Universal GPUs and seamlessly integrates hardware and software. MTT KUAE Platform for cluster management and MTT KUAE Model Studio for accessing model services fully support MTT KUAE to achieve maximum optimization. This end-to-end solution greatly simplifies the deployment and operation of large-scale GPU computational infrastructure.
MTT KUAE full-stack solution fully leverages the advantages of Moore Threads GPUs.
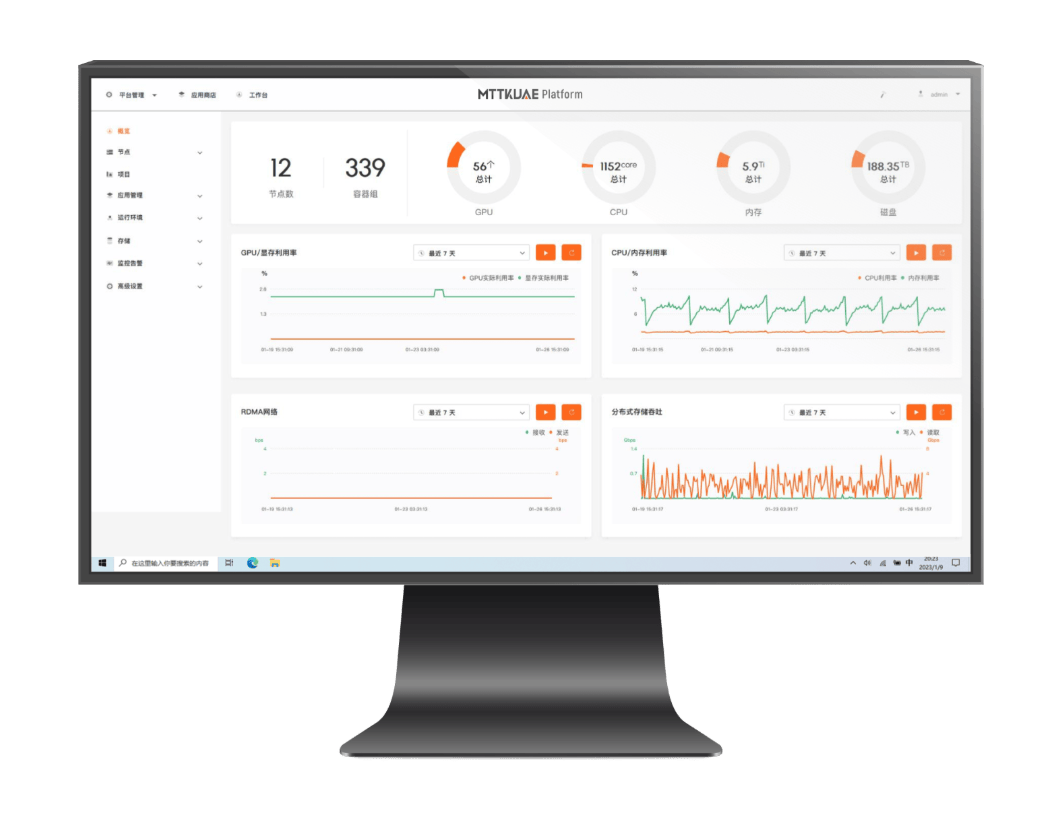
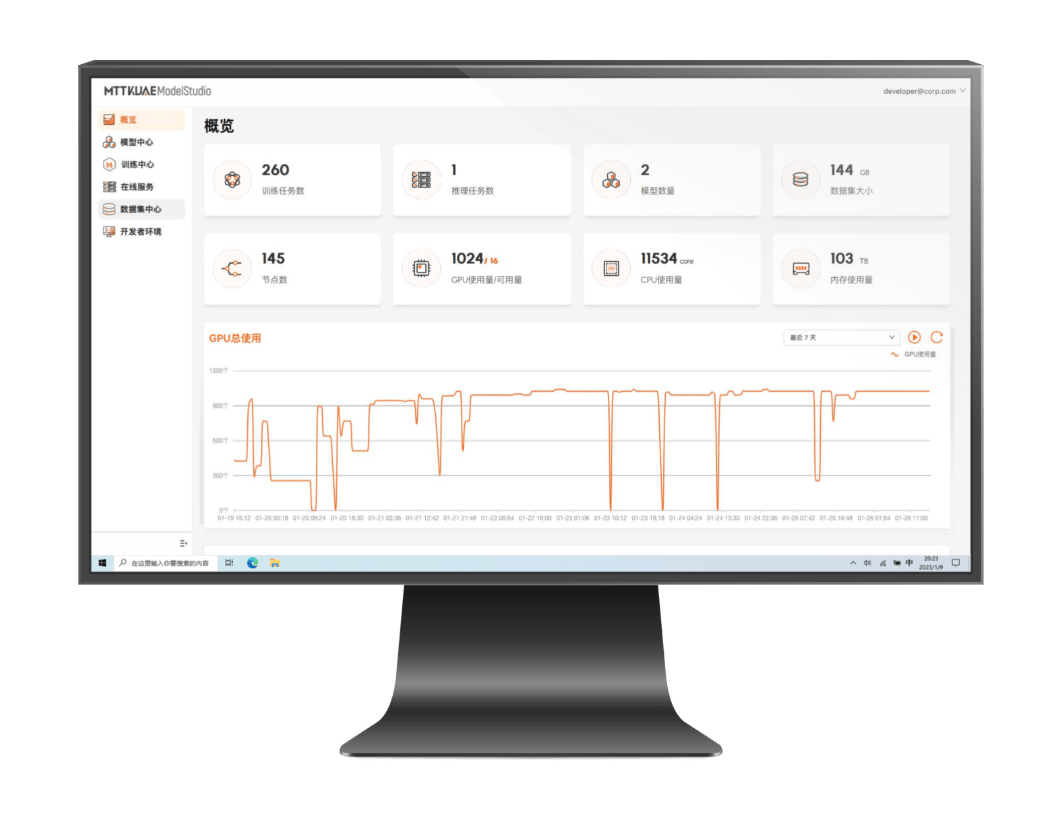

Modular design of large-scale GPU computing power with flexible deployment

Optimization of the linear speedup ratio of GPU computing power

Deployment of a high-speed parameter transmission network

Deployment and scheduling of heterogeneous computing clusters

Design and deployment of a computational power service support system
Scheduling of elastic computing power for cloud-native GPU clusters

Reliability and security of computing and storage

Highly reliable automatic problem diagnosis and recovery


Mon-Sun 9:00-21:00

