

400-667-5666
Mon-Sun 9:00-21:00
 中文
中文

MTT S4000 is a powerful GPU designed by Moore Threads for large models. It features the latest third-generation MUSA architecture, 128 Tensor Cores, 48GB of VRAM, and a blazing-fast 768GB/s memory bandwidth. Leveraging Moore Threads‘ innovative MTLink technology, it supports for multi-GPU interconnectivity to achieve clusters with thousands of cards and also accelerates computing for LLMs with a trillion parameters. MTT S4000 supports advanced graphics rendering, video encoding and decoding, and UHD 8K HDR display. With the full-featured MUSA architecture, it’s very convenient for customers to migrate their applications to MUSA platform.

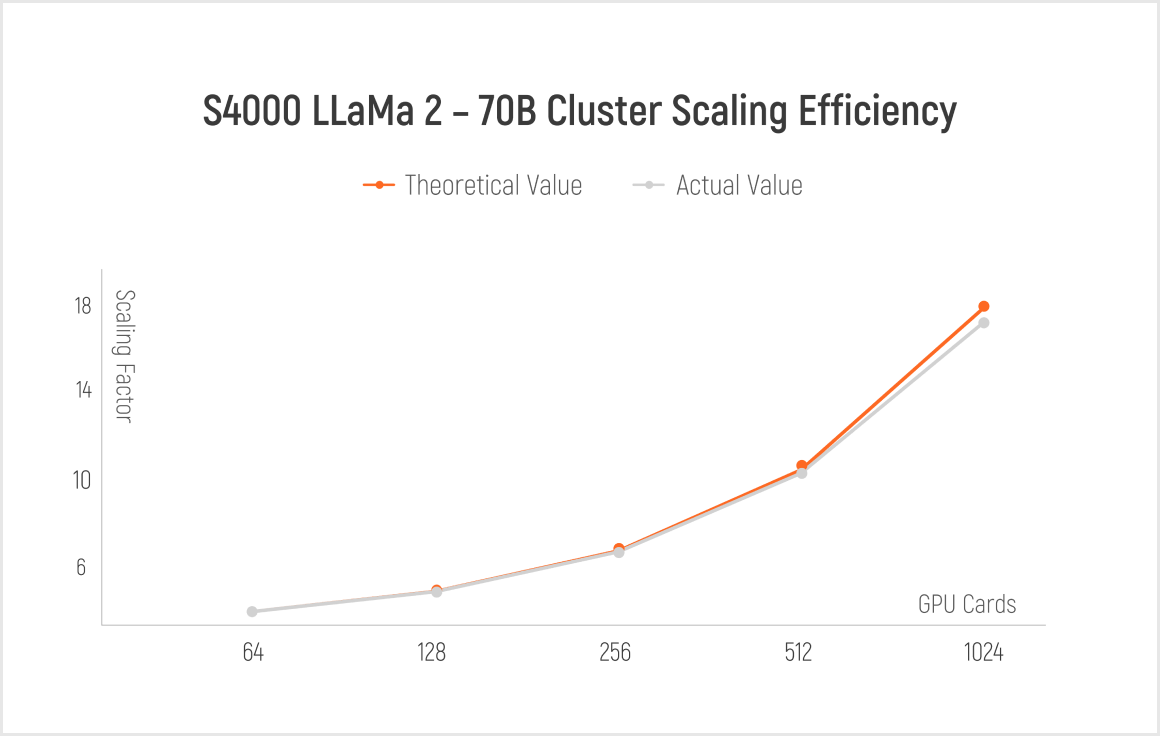
Perfect platform, mature MUSA ecosystem, MTLink interconnection, high MFU, and above 91% linear speedup ratio

Perfect inference platform, high throughput and low latency

Total solution with hardware and full stack software, high reliability, ready-to-use

128 Tensor Cores to accelerate LLM training, finetuning, and Inference

Full-featured MUSA architecture that is compatible with CUDA

Vulkan / DirectX / OpenGL / OpenGL ES supported
MTT S4000, equipped with 128 Tensor Cores and 48 GB of memory, effectively supports inference for mainstream LLMs, such as LLaMa, ChatGLM, Qwen, and Baichuan.
A training, finetuning, and inference platform for developers of LLM apps. It is based on Moore Threads' GPUs and models.
A software for high-performance and distributed inference services, supporting backend models such as LLMs, image and video generation, and traditional AI.
A distributed inference acceleration framework for Moore Threads' GPUs. It achieves inference acceleration for LLMs based on transformer architectures.
An inference acceleration framework for Moore Threads’ GPUs. It is ideal for inference acceleration in image and video generation and traditional AI.
MTT KUAE is Moore Threads' full-stack solution for artificial intelligence data centers. It is based on the S4000 GPU and MCCX D800 all-in-one cluster computing unit, which is equipped with eight dual-processor S4000 GPUs. This integrated solution tackles the challenges inherent in deploying large-scale GPU computing power with efficiency and effectiveness.
Moore Threads' advanced-generation Tensor Cores assist in the training, finetuning, and inference of LLMs. MTT S4000 includes 8,192 vector cores and 128 Tensor Cores. It supports mainstream precision computing formats such as FP64, FP32, TF32, FP16, BF16, and INT8.
MUSA is Moore Threads' self-developed metacomputing unified architecture, which includes an instruction set architecture, MUSA programming model, driver, runtime library, operator library, communication library, and mathematical library. CUDA programs can be smoothly migrated to MUSA through Moore Threads' self-developed MUSIFY tool.
MTT S4000 supports mainstream graphics APIs such as DirectX, Vulkan, OpenGL, and OpenGL ES. It provides versatile graphics rendering for a variety of scenarios, including digital twins, cloud gaming, cloud rendering, and content creation. It also supports large model inference capabilities, functioning as a one-stop solution for multi-modal scenarios like AIGC.


Mon-Sun 9:00-21:00

